Live Storage Device
Introduction
We program the LPC2148 board to function as a USB Mass Storage Device. Host machines see it as a drive with a FAT file system. However, this is not a true file system - the files represent various peripherals on the board. Writing or reading those files interacts with the peripherals in appropriate manner. For example, writing "1" to the file representing a LED turns it on, reading the button file tells us whether it is pressed, etc.
Motivation
Say you have a device and you'd like to be able to control it from a host computer. However:
-
You don't have a driver for the host's particular OS.
-
You don't have clearance to install a driver, software or reconfigure firewall.
-
You would like to use existing host's software to interact with the device in a simple ubiquitous manner.
LSD solves all of these problems - it doesn't require any installation or customization on the host's side. The only requirement is that the host can mount a filesystem from USB. If that is the case, then LSD works invariantly to the host's OS. Support of a particular filesystem is assumed - FAT12 is used in this implementation - but the device could be extended to support other filesystems as well.
Interaction with the device is done using regular IO to filesystem paths, which is supported by practically every application.
Usage
Simply attach the device to the host computer and wait for the OS to mount the filesystem.
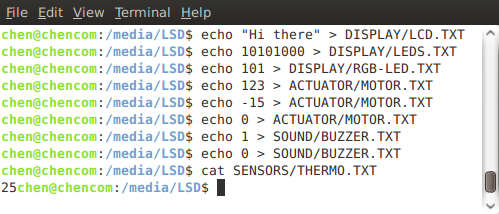
Each peripheral is represented by one or more files. Writing to a file associated with a peripheral activates it with the written data. For example writing "Hello World" to the file DISPLAY\LCD.TXT results in the appearance of "Hello World" on the device's LCD screen.
Reading a peripheral file shows its data. For example, the file SENSORS\THERMO.TXT contains the current temperature.
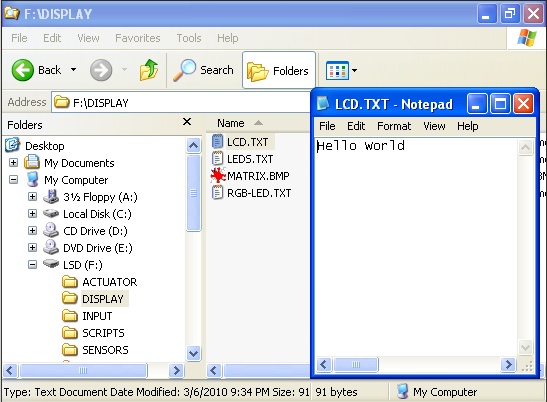 Editing LCD.TXT from the Display folder. Saving this file would cause "Hello World" to appear on the device's LCD display.
Editing LCD.TXT from the Display folder. Saving this file would cause "Hello World" to appear on the device's LCD display.
Reading and writing can be performed using ubiquitous applications such as Notepad on Windows or Pico on Linux. This is true for other file formats as well. For instance BMP files that represent matrices can be edited in Microsoft Paint on Windows or Gimp on Linux. Naturally, reading and writing can also be performed using the OS shell, scripting languages, shared filesystems, etc...
Controlling the device via Linux shell
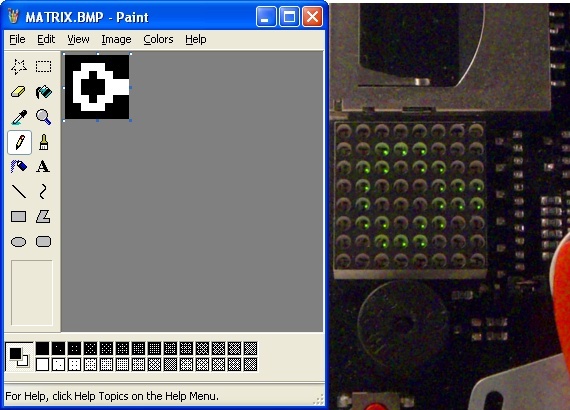
Manipulating the LED Matrix using Windows Paint
Limitations
LSD takes advantage of extremely undefined situations that OS and applications may or may not handle gracefully. For example, some text editing applications never directly edit a given file but instead work on a copy for backup reasons. This behaviour is problematic on our system as the filesystem pretends to be full, and thus the copy cannot be created. Some application don't handle this gracefully (e.g. Ubuntu's gedit).
A more serious limitation is the fact that the OS shows us a cached version of the filesystem - after the first read, we won't see any additional asynchronous changes. Unfortunately, there is no simple way to "refresh" the data. However, we provide an application for printing files that reads directly from the device by bypassing the cache altogether (more on this in the "Handling OS Cache" section).
Design
Mass Storage Device
Our device uses Mass Storage Device firmware that we adapted from an embedded programming project available online from Keil. It's not a complete implementation of a Mass Storage Device, but sufficient for our purposes.
Mass Storage Devices work through two USB endpoints.
On Endpoint 0, the control endpoint, they support two class-specific requests: Reset, which resets the firmware, and Get Max LUN, which returns the number of "logical units" in the device (not applicable in our case).
The actual data transfer is done through Endpoint 2, which is a Bulk Endpoint. Describing the entirety of the Mass Storage protocol is outside the scope of this document, but we will give a short overview.
The host sends packets called Command Block Wrappers (CBWs), which themselves (naturally) contain Command Blocks. These Command Blocks are simply SCSI commands - writes and reads for the most part. After receiving a CBW with a write command, the firmware will expect bulk transfers of the actual raw data to be written. Similarly, after a read command, the firmware will expect to be allowed to send the requested raw data to the host.
After completing a command, the device sends a Command Status Wrapper (CSW) packet back to the host, which tells it if the command succeeded, partially succeeded, failed, etc.
When it comes to actually reading and writing the data, the firmware interacts with our virtual FAT12 file system, which is described below.
Emulating FAT12
To the host, LSD identifies itself as a FAT12 volume. To do this, LSD has to interact with the host just like a valid FAT12 filesystem. This means that Read operations should return valid and consistent FAT12 data and Write operations must be carried out.
In terms of the Model-View-Control (MVC) Design Pattern the device's interaction with the host can be considered as the View aspect where FAT12 is the presentation format. The Model in that sense is the peripheral data and everything else is the Controller.
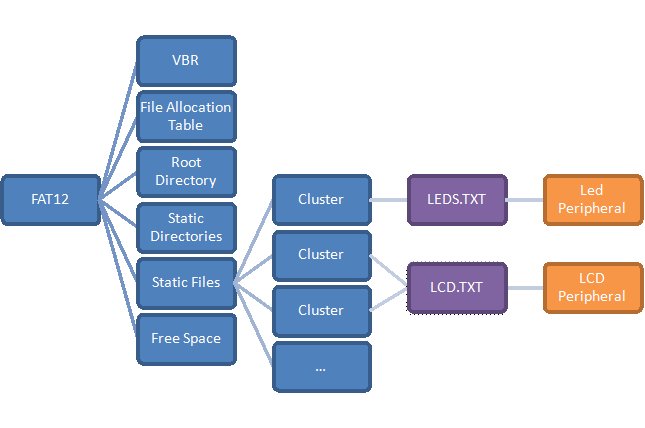
Following is a description of the various parts of FAT12 that we had to emulate:
Boot record
Once the host detects our device as a Mass Storage Device it attempts to automatically mount its filesystem. The host's operating system does this by reading out the first 512 bytes of the device (MBR/VBR). The VBR indicates the type of filesystem (FAT12), cluster size (512 bytes) and the location of the File Allocation Table. Our device interprets the request and returns bytes from a predefined 512 byte VBR block.
File allocation table
The FAT we use is two clusters long. FAT12 uses 3 bytes cluster addresses. To prevent the user from creating new files the FAT must not contain free clusters. We do this by initialising the table with 0xFFF.
Root and static directories
In FAT12, directories are specially flagged files, containing 32 bit records of file information. In FAT12 file names are restricted to 8 uppercase characters. We limited directories to a single cluster - 512 bytes. This means that we only support up to 14 files per directory (including ".." and ".").
Directory blocks are created in memory when initializing the device and returned to the host upon request. Since each directory takes a single cluster then the space allocated for all directories is (number of directories * 512).
Static Files
The actual content of files is stored here. This takes up most of the filesystem space. This section contains raw data without filesystem overhead. Each cluster is associated with a file datastructure which contains the actual data. One or more clusters can be associated with a single file where each cluster points to a different file offset. Thus the total number of clusters used depends on the amount of content. For example if README.TXT has 600 characters then it is associated with two clusters.
The file datastructure points to data that is either fixed or generated on demand (e.g. by a peripheral).
Address Space
|
Length
|
Name
|
0-511
|
512
|
VBR
|
512-1535
|
1024
|
File Allocation Table
|
1536-2047
|
512
|
Root Directory
|
-
|
#(Static directories)*512
|
Static Directories
|
-
|
#(Static file clusters)*512
|
Static Files
|
-
|
-
|
Free clusters
|
Map of our address space. Note that "Free Clusters" takes up whatever space remains.
Interpreting block operations
The SCSI protocol works with memory blocks. That is, it handles read/write operations for a consecutive address space.
To know what is at every address in the FAT12 filesystem we divided the address space into an hierarchy of so called "Segments". Each segment covers a predefined consecutive address block. Each segment may have child segments, and so on. For example, there is one segment reserved for file data, and each cluster in it is one of its child segments.
In addition to mapping the address space, segment objects are used for delegating operations. For instance the VBR Segment delegates operations to a fixed memory buffer. That is, when reading memory blocks associated with the VBR Segment, the device will write back bytes from the buffer, at the appropriate offset.
When the segment has children it propagates operations to them. For example the "Static File Data" Segment passes every operation on it to its children.
Note that block operations may include more than one segment. For example a single block read can theoretically include both VBR and FAT Segments. In that case the device splits block operations between child segments - each child segment gets its own independent block operation.
Data representation
Theoretically it would have been possible to maintain an actual representation of the entire filesystem in memory, consecutively. In that case, translating SCSI block operations to memory operations would have been trivial.
This is impractical in our case as the device's RAM is limited to a ridiculously low 32KB. Given that each FAT12 cluster is 512 bytes, and that an empty file takes as much room as a file with 512 characters, we would have been able to represent a theoretical upper bound 64 files (including directories!). In reality this bound would have been even lower (~14 files).
To address this problem, we developed a more memory-efficient approach in which the filesystem doesn't exist. Instead each segment object either returns data from memory or generates new data on demand. For example, reading the first 64 bytes from a file with a predefined maximum of 3 bytes would return the first 3 bytes from memory, while the remaining 59 bytes would be filled with zeros.
This considerably reduces memory demands and puts very little overhead on each new file. Given that there is a lot of redundancy in filesystems, more sophisticated methods can be used to reduce memory consumption even more.
Restrictions
Since we don't want file addresses to change, we prohibit the creation of new files. This is accomplished by making the filesystem appear full by filling the FAT with 1s (0xFF).
Note that we don't limit writes (unless written to non-existing space) and the OS is allowed to write to both static files and static directories. This is essential as FAT12 directory clusters contain "Size" and "Date" information for each file, which must be updated for each write.
Peripheral files
Peripheral files are special files in the filesystem that are associated with different peripherals. They are treated like regular files, but after being written their associated peripheral is invoked with the contents of the file. For example after writing to bytes 32 to 63 of \DISPLAY\LCD.TXT, the LCD peripheral handler is passed with bytes 0 to 63.
This means that if block operations are 32 bytes then writing 64 bytes to the LCD file will invoke the LCD handler function twice, causing the display to slightly flicker. Although not currently implemented, this can be easily handled by waiting for all writes to complete before invocation.
Reading peripheral files is performed in a similar way. Before reading a peripheral file's data, the peripheral is invoked and its content is read to the file. Then the appropriate data from the file is returned.
Schematic breakdown of the LSD core. FAT12 segments are in blue, files in purple and peripherals in orange. Here LCD.TXT is shown spanning two clusters (just for illustration; in our implementation it takes one cluster).
Peripherals
We created a peripheral framework that allows easy addition of peripheral functionality to the device, and also automatically handles resource conflicts between peripherals. Each peripheral has an ID number, which can be used to index into a data structure that contains all necessary information and functionality required to interact with the peripheral. To be specific, this data structure contains:
-
A setter - changes the peripheral's state.
-
A getter - gets the peripheral's current state.
-
An initialization function - initializes the peripheral, acquiring all necessary resources and preparing it for repeated setting or getting.
-
A disable function - disables the peripheral. Used if it conflicts with other peripherals that need its resources.
-
The peripheral's data type - binary number, decimal number, or string.
-
The peripheral size - the number of bytes required to store the peripheral's current state. Required by the virtual file system to provide buffers of appropriate sizes.
-
The pins used by the peripheral - required to correctly settle conflicts between the peripherals over pins.
We'll describe the conflict resolution mechanism in greater detail. Each peripheral has pins that it requires in order to operate. Furthermore, some peripherals will need a particular pin to be an output GPIO pin, other peripherals will need it to be an input pin, or need it to be connected to the I2C block, etc.
Rather than reinitialize all of a peripheral's pins on every single access, which might corrupt the peripheral's state, we have a Pin Control module that keeps track of which peripheral "owns" which pins. If a peripheral needs to be initialized, it first asserts control of all of its pins via the Pin Control module. The Pin Control module will automatically disable all other peripherals that are using those pins, and mark them as uninitialized. If any of those peripherals is accessed in the future, it will need to reassert control of its pins and reinitialize, in the same way.
To sum everything up, the only thing necessary in order to work with a peripheral is its ID. When setting a peripheral, we initialize it if necessary, convert the raw data written to the virtual file system to the appropriate data type, and call the setter. When getting, we initialize if necessary, call the getter, and convert the result from the appropriate data type back into raw data.
Supported Peripheral List
LED Array - turn each LED on or off
RGB-LED - turn each color on or off
LED Matrix - display any 8x8 image
LCD Display - display any string
Button - check if button is pressed (read only)
Joystick - check where joystick is pointed (read only)
Buzzer - turn on or off
Step Motor - set motor rotation speed (can also be negative to rotate backwards)
Thermal Sensor - read temperature (read only)
Handling OS Cache
"The whole notion of 'direct IO' is totally braindamaged. Just say no.
This is your brain: O
This is your brain on O_DIRECT: .
Any questions?"
Linus Torvalds when asked if it's possible to mount a filesystem without caching [ref]
Operating Systems always use caching when handling storage devices because otherwise IO with hard drives and floppies would be too slow. This principle is so ingrained that it is almost impossible to disable caching without using hacks.
For write operations, things are usually OK. By default modern OSes use write-through caching which synchronizes writes with the device, and there are conventional ways to instruct the OS to flush writes.
However when it comes to reading, caching is strictly enforced.
There are three approaches to handling this limitation:
1. Remounting the device each time new data is to be read.
2. Forcing the OS to flush the cache.
3. Using direct IO.
Each approach is OS-dependent and unfortunately there is no solution that works for both Windows and Linux. While remounting would work, it's too crude a method. Instead we focus on the other two solutions:
Drop Caches
This approach tries to force the OS to flush the cache and reread from the device. Until recently there wasn't a conventional way to do this under Linux. The only solution was to push more and more data into the cache, forcing it to purge older information. Luckily, starting from Kernel 2.6.16 there is a a new convention. Writing a number to /proc/sys/vm/drop_caches will cause the OS to purge all cached data:
echo 1 > /proc/sys/vm/drop_caches
However, this is probably overkill as it forces all cached data to drop and not just the device's. A more serious downside is that this action requires root priviliges, thus not making reads as ubiquitous we'd like.
Direct IO
"There really is no valid reason for EVER using O_DIRECT."
Linus Torvalds
Both Windows and Linux provide a way to directly access the device, completely avoiding the cache. These methods are called Direct IO and using them is discouraged because they are much slower than cached IO. In fact they are almost exclusively used by benchmark programmers and database programmers that wish to implement their own cache system. Thus programs that already use Direct IO are anything but common.
However writing a short application that prints the content of the file using direct IO is possible. Doing so is a bit complicated due to some restrictions, but basically (using GCC) one opens a file using the special flag O_DIRECT. The following is a small program we created for direct read which prints a given file's actual content to stdout:
#define _GNU_SOURCE
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
char BUFFER[513] __attribute__((aligned(512)));
int main(int argc, char**argv) {
if(argc<2) {
puts("Usage: dread <filename>");
return -1;
}
int fd = open(argv[1],O_RDONLY|O_DIRECT);
if(fd<0) {
puts("Bad filename!");
return -1;
}
ssize_t len;
do {
len = read(fd,BUFFER,512);
BUFFER[len] = '\0';
printf("%s",BUFFER);
}while(len==512);
puts("");
return 1;
}
For Windows a similar solution exists, using the flag FILE_FLAG_NO_BUFFERING when calling the WIN32 function CreateFile.
Although existing software almost never uses direct IO, many operating systems do allow it and thus it is possible to store binary executable files on the device that do this for each operating system, thus making reading as ubiquitous as writing.
Actual File Storage
Since we've implemented a Live Storage Device, we might as well use it to store actual files. Thus, we've created a mechanism to automatically write native files to the device and access them from the LSD. Basically, we had to convert files into object files and link them with the rest of the program.
There are many ways to generate object files. For maximum compatibility we chose to automatically convert files to byte arrays, all located in a single C syntax file. Each file's content is addressed using the array identifier.
Marking these files as const ensures that they are written to the EPROM instead of the RAM, thus theoretically allowing ~500KB worth of data.
Implementation
The LSD project is hosted on Sourceforge: http://sourceforge.net/projects/vfat/
Compiling under Linux
First install gnuarm toolchain. This script proved very helpful:
http://blog.nutaksas.com/2009/05/installing-gnuarm-arm-toolchain-on.html
Then download lpc21isp from:
http://sourceforge.net/projects/lpc21isp/
To compile LSD you should create your own version of makefile.local and set your local paths and preferences. Then burn the application to the device by running:
make program
Tests
Since LSD is so easy to control, we used batch files to activate the device with reads and writes to verify that it works. A Bash test script resides under the test directory.
Tutorial
To demonstrate and test the power of LSD under Windows, we have a batch file that uses LSD and explains its doings in a human readable form. All operations are performed using ECHO for writing data and our own direct IO application for reading.
To play the tutorial simply run test/TUTORIAL.BAT under Windows.
The first screen of the demonstration batch script
3rd Party Code
As mentioned above, the core Mass Storage Device firmware was adapted from a project for the Keil MCB2140 Evaluation Board (available here:
http://www.keil.com/download/docs/307.asp). This is a complete project, including its own USB firmware, which doesn't work on our LPC2148 Education Board of course. And, of course, rather than implement a virtual file system as in our project, it just has a big array to contain all data.
We had to rip out the Mass Storage portion of Keil's code and connect it to our own USB firmware (from the course website).
On the USB side, we had to add callbacks to the class-specific requests and to the endpoint handling functions. We also had to convert the Mass Storage Device USB descriptor from Keil's code to the same format used by our code.
On the Mass Storage Device side, we had to point to our alternative functions for writing, reading and stalling the endpoints. And, of course, once we had the virtual file system up and running, we had to modify the Mass Storage Device code to use that rather than the big array.
Licensing
Our code is licensed by the GPLv3 and is available online at Sourceforge.net. Unfortunately this conflicts with Keil's licensing which prohibits distribution of its source files (but permits use of binaries). Thus technically the modified Keil source files can't be legally distributed with the rest of our code.
Conclusions
From the start we were completely aware that the LSD concept is a total hack that violates every storage device taboo. Thus we were very much surprised to see that more often than not, it actually worked quite well! This may not have been true in every case with every software application, but for the most common usage, it surpassed our expectations.
While this was a fun project in embedded programming and it taught us a great deal, we also hope that this system will be beneficial to someone somewhere who requires LSD's ubiquitous interface. Just because it isn't guaranteed to always work doesn't mean that it's not useful!
Future work
Our system imposes extreme restrictions such as not allowing new files to be created and old ones to be moved. This is especially problematic with badly written software that insists on changing file addresses (by creating a new file and deleting/renaming the old).
Thus a more robust approach is to identify a file by its name and not by its address. This approach is certainly possible, but requires a great deal of further development.